房产是一个人一生中的核心资产,而房地产行业以北上深一线大城市最为发达,需求最旺盛,本项目利用爬虫爬取链家网北京市二手房信息,对于普遍关注的问题和影响房价的相关因素,通过探索性数据分析找出答案,再建立机器学习模型实现随行就市的自动化房屋价格预测。
项目目的:
通过实际数据针对以下问题进行分析
- 北京二手房整体价格分布
- 各行政区房价差异
- 房龄在2000年以后的房源在各行政区的分布
- 房龄对房价的影响
- 电梯对房价的影响
- 最受关注的房源有哪些特点
- 首付100万以内能买到哪些小区
- 通过相关系数矩阵选取影响房价的特征
- 建立机器学习模型评估房价
- 模型评价
技术和工具
项目主要分为三部分,以Python编程语言为基础,第一部分是数据爬取,主要用到网页解析库BeautifulSoup。第二部分是数据分析,使用pandas作为数据处理和统计分析的工具,以matplotlib,seaborn库实现图形的可视化。第三部分是机器学习建模,用到scikit-learn中的三种回归建模模型,分别是线性回归、岭回归、支撑向量机,并用GridSearchCV对岭回归参数alpha进行交叉验证调优。
准备工作
数据获取
项目所使用的数据集全部来自链家网,通过BeautifulSoup爬取链家北京二手房100页房源数据。
1 |
for i in range(1,101): |
分别提取房源单价、房源总价、房源位置、关注度等信息,得到3000个样本数据: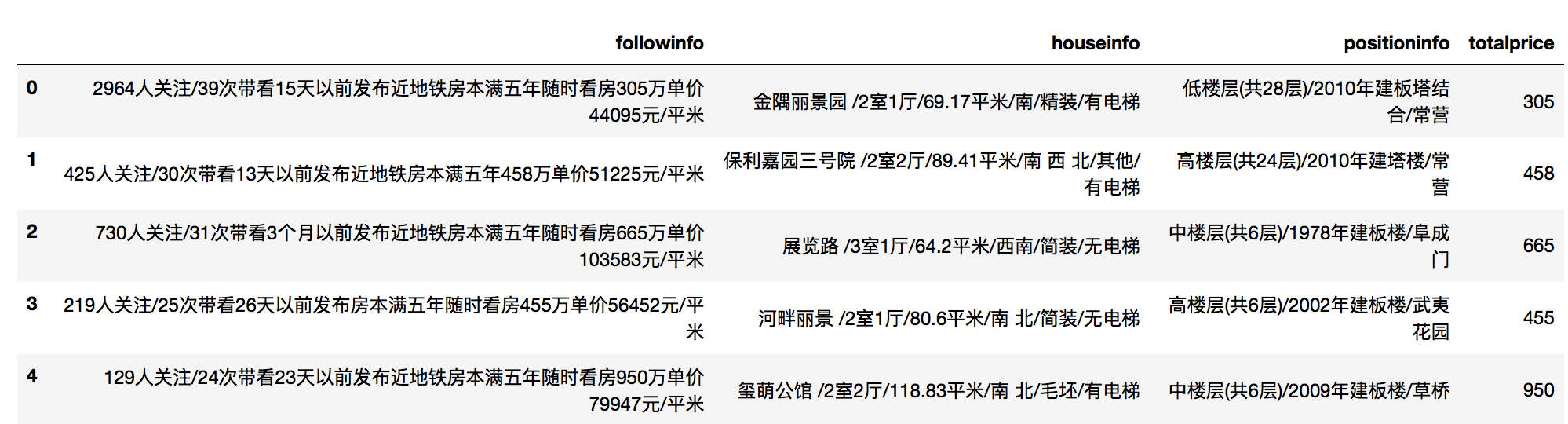
数据清洗
保留全量数据,对缺失值、无效值等进行处理:
1 |
#处理房源面积数据 |
处理后得到2732个样本数据,最后保留属性小区名称community、户型apartment、面积size、装修decoration、电梯elevator、地址address、关注度attention_rate、建造年份year_built_feat 、行政区域district_name、总价totalprice、单价unit_price、楼层floor、建筑类型building_type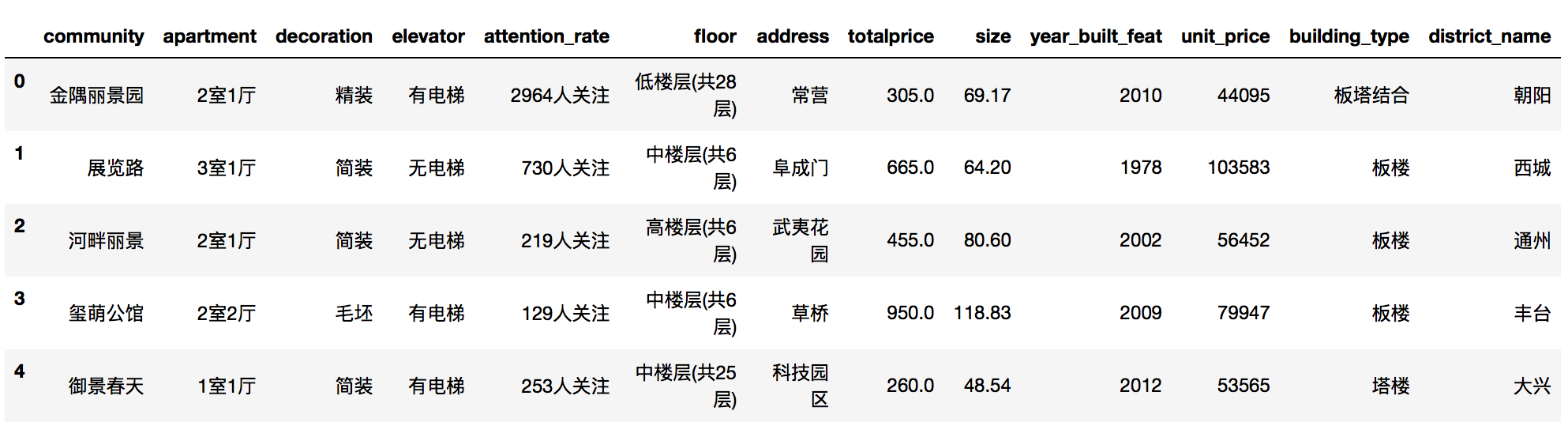
数据分析( 探索分析 )
北京二手房整体价格分布
1 |
price=house_datas['unit_price'] |
北京市二手房最高价格:149926.00元/平方米
北京市二手房最低价格:18590.00元/平方米
北京市二手房平均价格:67106.07元/平方米
北京市二手房中位数价格:62508.50元/平方米
北京市二手房众数价格:49505.00元/平方米
从统计结果上来看,北京二手房最高价与最低价格相差近13万元/平方米。房价的平均数>中位数>众数,呈右偏分布。接下来展示整体二手房价的分布:
1 |
#绘制房价分布直方图 |
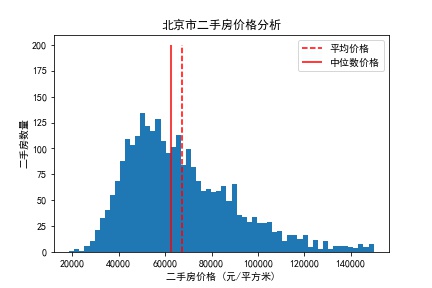
从房价整体分布图来看,受极大值较多的影响,数据呈右偏的正态分布。考虑到北京城区和远郊区县价格相差悬殊,接下来我们看行政区的不同对房价的影响
各行政区房价差异
1 |
#可视化 各区域房源单价均价 |
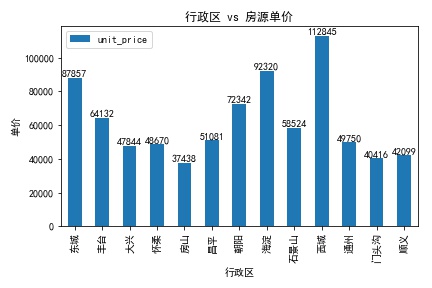
可以看到由于教育资源和地理位置的优势,西城均价最贵,其次是海淀、东城、朝阳。通州的房价在意料之外,通州作为北京的副中心,但均价还不到5万,可见限购政策收紧了流动性,对房价影响较大。大兴、顺义、怀柔等远郊区县价格相差不大,又以房山价格最低。接下来进一步查看各行政区内部的房价分布,通过箱形图展现:
1
2
3
4
5
6
7
8
9
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei')
sns.boxplot(x='district_name',y='unit_price',data=house_datas)
plt.title("北京市各行政区二手房价格分析(箱形图)")
plt.xlabel('行政区')
plt.ylabel('单价(元/平方米)')
plt.savefig('./pics/box_price.jpg')
plt.show()
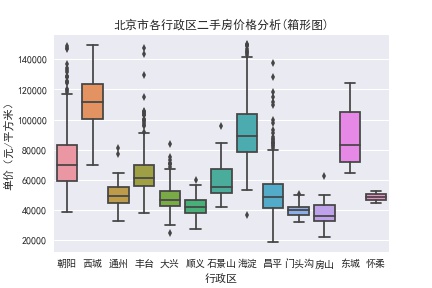
从图中不难得出结论,西城和海淀的高价房使得北京整体房价分布呈现右偏的态势。
可以看到海淀、朝阳、昌平的上侧异常值较多;而西城和东城房价虽高,但分布均匀,没有异常值出现,这应该和占地面积有关,比如海淀区全区占地面积426平方公里,东城和西城是40-50平方公里,相差近10倍,所以东西城房源位置集中,又都属于核心区域,房价分布更加均匀。而海淀、朝阳、昌平都是大区,房源分布分散,海淀最高房价超过14万,最低不到6万,所以刚需家庭或有落户需求的家庭可以在海淀、朝阳的非核心区域寻找购房机会。
2000年以后建成的房源在各行政区的分布
考虑到投资房产因房子折旧带来的折价和产权剩余的时间,购房者可能会关注房子的房龄,先看一下各行政区房源数量的分布情况:
1 |
#可视化 各区域房源数量比例 |
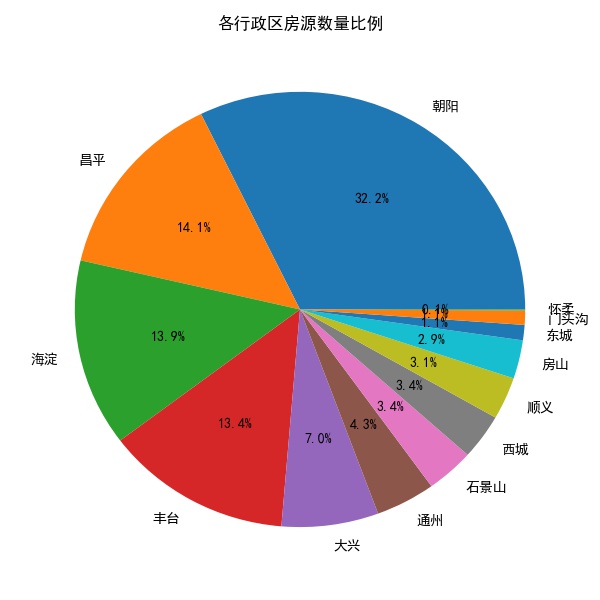
朝阳区的房源最多,其次是昌平、海淀、丰台。
进一步看房龄在2000年以后的房源和房源总量的比较:
1 |
house_new=house_datas['district_name'][house_datas['year_built_feat']>=2000].value_counts() |
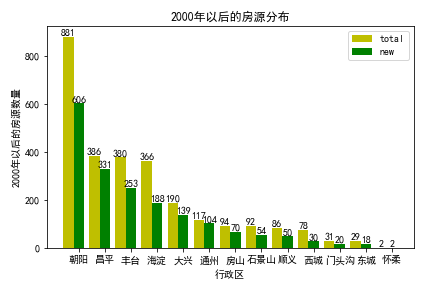
房龄在2000年以后的房源依然是朝阳区最多,从比例来看,远郊区县大部分房源都是新房,西城区大部分是2000年以前的老房,但西城房价是所有城区最高,与需求完全不对称的供给,加上全北京最优质的教育、医疗成就了西城“高价老破小”的神话。
对比朝阳和海淀,海淀新房老房的数量都小于朝阳,且海淀拥有更好的教育资源和去哪都近的区位优势,为海淀房价提供了更好的支撑性。
房龄对房价的影响
考虑各行政区的房价差异较大,房龄的影响也要按区分析,取海淀和西城的数据来分析:
1
2
3
4
5
6
7
8
house_haidian=house_datas[house_datas['district_name']=='海淀']
plt.scatter(x="year_built_feat", y="unit_price",data=house_haidian)
plt.title('海淀区房龄与单价散点图')
plt.xlabel('建造年份(年)')
plt.ylabel('单价(元/平方米)')
plt.tight_layout()
plt.savefig('./pics/house_haidian.jpg')
plt.show()
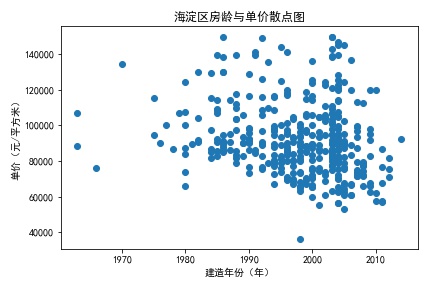
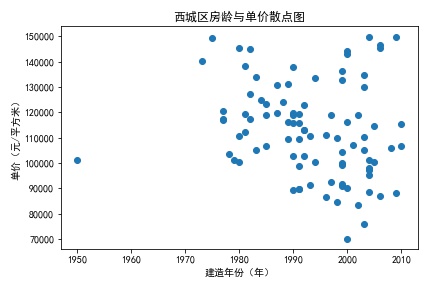
结果比较意外,房龄的因素对房价影响不大,这说明在有限的优质资源面前,需求和供给的严重不平衡削弱了房龄对价格的影响。
电梯对房价的影响
1 |
#可视化 电梯对房价的影响 |
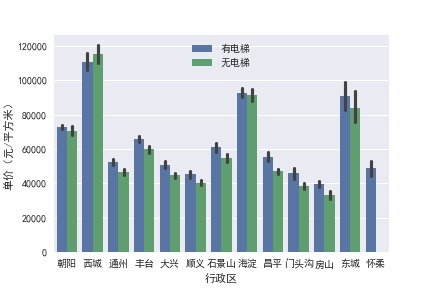
除了西城,有电梯的房价都高于无电梯房屋。
最受关注的房源有哪些特点
取关注度排名前100的房源进行分析,先看电梯、房型对关注度的影响:
1
2
3
4
5
house_attention=house_analysis.head(100)
sns.swarmplot(x="elevator", y="attention_rate_feat", data=house_attention, hue='apartment')
plt.ylabel('关注度')
plt.legend()
plt.savefig('./pics/attention_apartment.jpg')
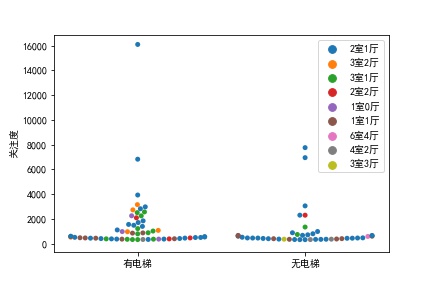
从统计结果可以得出,关注度最多的房型是2室1厅,但对有无电梯并不敏感。
同样的方法对其他属性进行分析,得到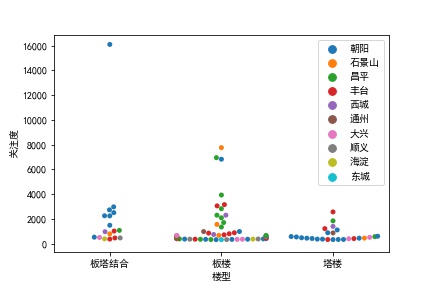
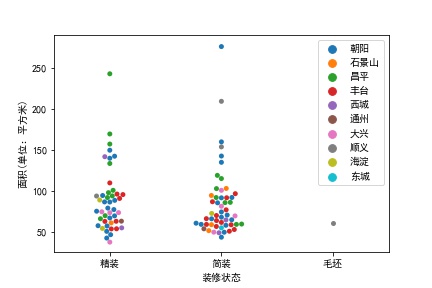
综上分析,人们对户型为2室1厅、面积在100平方米以下、楼型是板楼的房源关注度最多。
首付100万以内能买到哪些小区
以公积金贷款为例,统计100万以内的首付能买到哪些房源:
house_limit=house_datas[(house_datas['totalprice']-120)<=100]
import seaborn as sns
sns.barplot(y='community',x='unit_price',data=house_limit,hue='district_name')
plt.xlabel('单价(元/平方米)')
plt.ylabel('')
plt.legend(loc='upper right')
plt.savefig('./pics/price_limit.jpg')
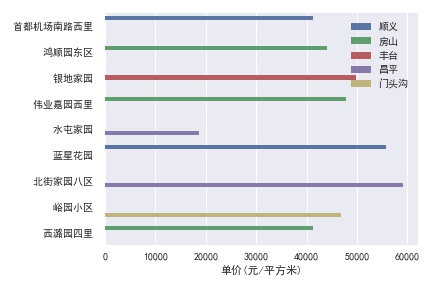
结果并不乐观,100万只能买到丰台一个房源,远郊区县也仅有8个房源。
房屋价格预测
绘制相关系数矩阵,选取影响房价的特征
#计算变量之间的相关系数矩阵
correlations =house_var_relation.corr()
sns.heatmap(correlations,cmap="YlGnBu")
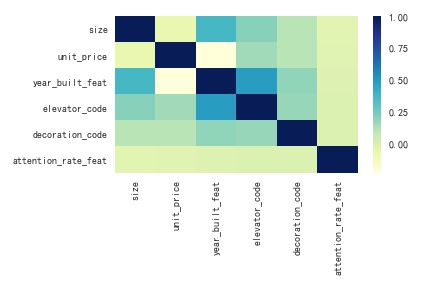
从图中可以看出,户型和面积、电梯和房龄相关性较强,如前面分析,房价和房龄相关系数很小。所以最后选取特征户型、面积、电梯、装修、行政区来预测房价。
建立机器学习模型预测房价
采用机器学习方法综合考虑多个因素对房价的影响,并建立预测模型。当前数据有5个特征(房屋面积、所在行政区、户型、电梯和装修)和1个标记(房价)。因为预测目标——房价是一个连续变量,因此本项目中的价格预测是一个回归问题, 常见的机器学习回归模型有线性回归、岭回归、支持向量机和随机森林等。本项目中选取三类模型(线性回归、岭回归、支持向量机)进行房价预测。
数据预处理
def house_preprocessing():
df = pd.read_csv("./house_var_relation.csv")
#得到标注
label=df['unit_price']
df=df.drop('unit_price',axis=1)
#特征处理,数据min-max归一化
column_lst = ['size', 'elevator_code', 'apartment_code','decoration_code']
for i in range(len(column_lst)):
df[column_lst[i]]=\
MinMaxScaler().fit_transform(df[column_lst[i]].reshape(-1, 1)).reshape(1, -1)[0]
# 使用one-hot编码修改特征"district"
df = pd.get_dummies(df, columns=['district_name'])
return df,label
把单价unit_price设为标注label,行政区采用one-hot编码,面积size等特征使用min-max归一化
参数调优
对于岭回归,使用GridSearchCV网格搜索的方式对alpha参数进行调优
param_grid={'alpha':[i for i in np.arange(0,1,0.1)]}
rid=Ridge()
grid_search=GridSearchCV(rid,param_grid,verbose=1)
grid_search.fit(X_tt,Y_tt)
print(grid_search.best_score_)
print(grid_search.best_estimator_)
得到best_score0.55,此时alpha=0.1
模型训练与评价
def house_modeling(features,label):
from sklearn.model_selection import train_test_split
f_v=features.values
f_names=features.columns.values
l_v=label.values
#样本分为训练集,验证集,测试集
X_tt,X_validation,Y_tt,Y_validation=train_test_split(f_v,l_v,test_size=0.2)
X_train,X_test,Y_train,Y_test=train_test_split(X_tt,Y_tt,test_size=0.2)
from sklearn.metrics import r2_score
from sklearn.svm import SVR
from sklearn.linear_model import LinearRegression,Ridge
from sklearn.ensemble import RandomForestRegressor
models=[]
models.append(("LinearRegression",LinearRegression()))
models.append(("RidgeRegression",Ridge(alpha=0.1)))
models.append(("SVR Regression", SVR(C=1000,kernel='linear')))
#输出各model在训练集、验证集、测试集的R2
for clf_name,clf in models:
clf.fit(X_train,Y_train)
xy_lst=[(X_train,Y_train),(X_validation,Y_validation),(X_test,Y_test)]
for i in range(len(xy_lst)):
X_part=xy_lst[i][0]
Y_part=xy_lst[i][1]
Y_pred=clf.predict(X_part)
print(i)
print(clf_name,"R2:",r2_score(Y_part,Y_pred))
三种模型比较结果如下:
| 线性回归 | 岭回归 | SVR | ||
|---|---|---|---|---|
| 训练集 | 0.56 | 0.56 | 0.47 | |
| R方得分 | 验证集 | 0.55 | 0.53 | 0.42 |
| 测试集 | 0.55 | 0.57 | 0.42 |
R方得分越高,模型的预测能力越强。由此看出线性回归和岭回归差别不大,SVR的预测能力最弱,但通过调参和交叉验证的方法可以进一步训练模型,提高预测能力。
岭回归预测效果: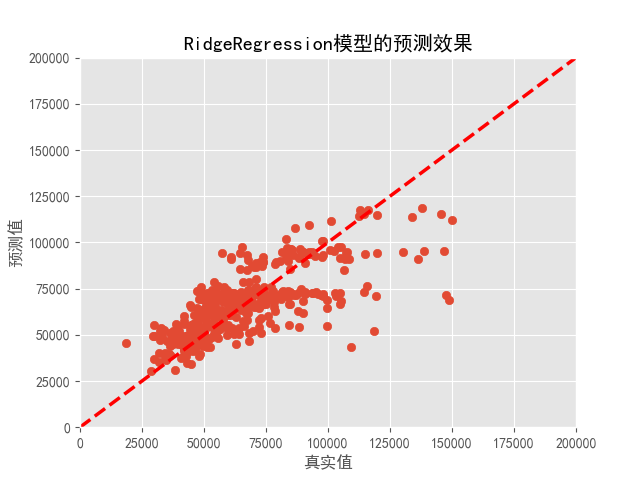
可以看到岭回归在低房价区间预测效果较好,但随着房价超过75000/平方米后预测能力减弱。
项目小结:
本项目根据链家网爬取的数据,对影响房价和关注度的因素进行了简单数据分析。项目还有很多可以改进的地方,如可以根据房屋的具体地理位置(离地铁或商圈的距离)深入分析对房价的影响,对机器学习模型进行调参和融合进一步提高预测能力,从而为购房者提供建设性意见。