基于爬虫技术的事件驱动策略-券商评级变动事件驱动策略
策略思想:
- 机构会发布针对个股的研报,研报中会对个股做出一个建议评级
- 跟踪机构研报对个股的评级变化,个股评级上调为“强烈推荐”作为买入信号,持有2个月(约40个交易日)
策略规则
- 从和讯爬取研报评级变动数据;
- 使用评级变动数据形成买入信号;
- 结合个股每日收益计算策略收益率
策略实现
爬虫获取网页数据
获取页面源代码
通过request获取页面源代码,用BeautifulSoup进行解析:
1 |
import urllib.request as request |
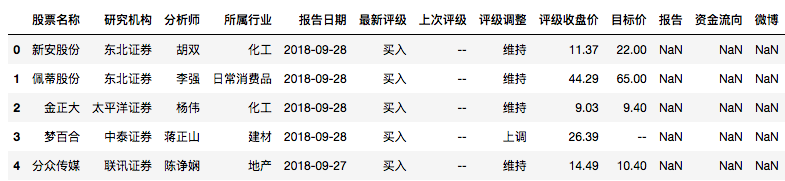
评级跟踪策略
策略规则
读取评级数据和下载好的所有股票的日收益率数据
1 |
data = pd.read_csv('data.csv') |
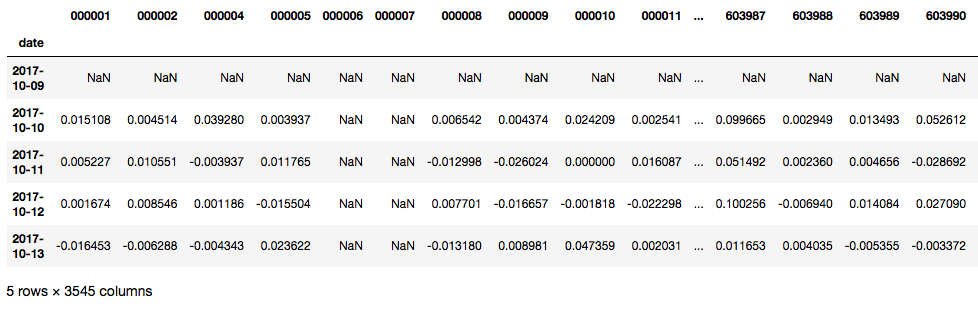
策略回测
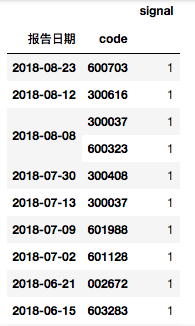
标记个股券商研报评级调升日期
1 |
signal = data.loc[(data['最新评级']=='强烈推荐') & (data['评级调整']=='上调'), ['code', '报告日期']].dropna().drop_duplicates() |
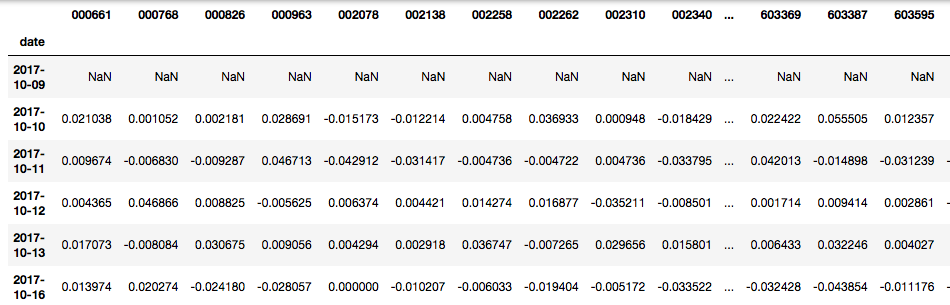
从日收益率数据中筛选出研报中出现过的股票
1 |
selected_codes = signal.index.levels[1].unique() |
用等权重法计算投资组合的每日收益率
1 |
signal_cross = signal.signal.unstack() |
以沪深300为benchmark做出净值曲线
benchmark_return = ts.get_k_data('hs300', '2017-10-08', '2018-09-28').set_index('date').close.pct_change()
benchmark_return.to_csv('benchmark_return.csv')
returns = pd.concat([portfolio_return, benchmark_return], axis=1)
returns.columns = ['portfolio', 'benchmark']
returns.index = pd.to_datetime(returns.index)
net_values = (returns + 1).cumprod()
net_values.plot(figsize=(10,6))
plt.show()